“建议专家不要建议”为什么是对的?
2023-06-23
更新时间:2023-06-23 08:35:02 作者:知道百科
“建议专家不要建议”为什么是对的?
过去的这个周末,人教版教材问题持续发酵,专家和机构的公信力再一次遭遇危机。
这让我们联想起两周前,有一句话反复上了热搜,叫“建议专家不要建议”。
当时就有媒体分析网友为什么不待见专家,大多数谈的都是“公共话题”这一类方向。
网友对专家不买账,一方面是认为“专家站着说话不腰疼”,给建议不接地气,当然另一种情况是,如果专家本身“屁股就坐歪了”,那民众不但不能相信,还要问责。
不过以上都属于专家的主观层面,我们要说的,是一个“建议专家不要建议”的客观依据:
相信专家,你还真不如去相信机器。

就算你对专家不感冒,这个结论也多少有点反直觉,下面我们还是举一个招聘的例子。
想象你是一个校长,你们学校要招一位行政主管。现在有两位候选人,在此之前,两位候选人经过了层层面试,前几轮的面试官分别从5个维度给两位候选打了分(10分满分),以下是他们各项得到的平均分:
候选A:领导力7分,表达能力6分,人际交往7分,业务技能8分,自我激励8分
候选B:领导力8分,表达能力10分,人际交往6分,业务技能5分,自我激励5分
请问校长,您觉得应该要谁呢?
我们大概可以总结三种比较的思路:
1、最简单粗暴的,把每个人五项的分数再平均一次,在这里A是7.2分,B是6.8分,所以要A。
2、往深想一层,A好像各方面能力比较平均,而B有一个明显的长处,就是表达能力,10分是什么概念,就是前面所有面试过他的人都给了满分,行政岗位,沟通表达能力是不是要比业务技能重要?如果是,那应该选B。
3、再往深想一层,表达能力是重要,可是有多重要呢,比业务技能重要一倍?两倍?所以是不是应该结合一些数据,对这五个指标做加权平均,这样算出来的结果才更科学吧?
这里面,“思路2”是一种基于个人经验和直觉的判断,我们称之为“临床判断”。专家们做出的判断,基本都属于“临床判断”,因为这个判断一定要包含专家本人的主观经验(比如认为表达能力是核心指标)。
而与之相对的,“思路1”和“思路3”就叫做“机械判断”,是基于数据的一种判断,其中“思路1”是简单模型,“思路3”是复杂模型。
按照我们一般人的判断,这三种思路,“思路1”好像是最不讲道理的,所以是一个最差的策略,但真正的结论是:
“机械判断”强于“临床判断”(也就是专家判断),而“简单机械判断”也并不比“复杂机械判断”逊色。

刚才我们说的,候选A和候选B的案例来自一项真实的研究,其中“思路2”(也就是重视表达能力)这个临床判断,是众多专家模型中比较典型的一款。
结果是,一群专业的心理学家,各自做了预测模型,但这个结果和实际工作表现之间的相关系数,只有0.15,这意味着专家的判断跟扔硬币效果差不多。
这个研究并不是孤例。早在2000年,有人曾综合调查过136项研究,包括了各式各样的预测主题,比如黄疸病的诊断、服兵役的适应性、婚姻的满意度等等比较复杂的判断,结果是:
其中63项机械判断更准确,65项是机械判断和临床判断同样好,而只有8项是临床判断更好。
这里我们还没有计算决策的成本问题,机械判断显然比临床判断快得多,而且根本不需要请专家,可谓省时省力省钱。
可这是为什么呢?奥秘其实很简单:只要是人做判断,就必定会伴随各种不可预知的干扰,我们之前有介绍过,这个东西叫做“噪声”。(点击回顾关于“噪声”的解读)
还是开头的例子,为什么专家不会同意简单的取平均分方法呢?因为专家认为这太一刀切了。
比如我们都听过,有的数学天才,从小就是迷恋数学,但是英语非常差,如果取平均分,那这种数学天才肯定上不了大学了,我们不应该仅仅因为英语不好就抹杀一个天才,对吗?
专家的逻辑是:我们应该具体问题具体分析。这听起来好像非常合情合理。
但是请注意,毛病恰恰出在这里——
我们往往高估了“具体问题具体分析”的有效性和可实操性。
开头例子里的候选B,表达得分是满分10分,这真的说明他是一个表达天才吗?在只有两个候选人的情况下,其中一个人表达得到了10分,这个10分只能被看做是一个“比较级”,而很可能不是“最高级”,这种情况下押宝在一项指标上,很冒险,并不靠谱。
更有可能的情况是:你以为的特殊情况,只不过是一般情况,你给自以为的特殊情况打了满分,这个分数虚高的可能性,要大于他真的值一个满分。
所以“英语差的数学天才”,这个故事模型也是经不起实操的,极少数真正的天才,的确可以通过自主招生之类的方式被录取,但99.99%的学生不可能走这条路——
 到韦神这个级别,也许可以聊聊保送北大的事
到韦神这个级别,也许可以聊聊保送北大的事你以为自己是个数学天才,其实放到最顶级的那群人中间,可能又相形见绌了,所以想考好大学,请尽量把各科分数都提上去。这本身就是最公平的选拔方式。
我们来总结一下,机械判断和临床判断的区别到底是什么:
机械判断的不足是,好像抹杀了一些“特殊情况”,缺少“微妙考虑”,但研究结果告诉我们,这些所谓微妙考虑带来的收益,不如那些噪声的破坏力大。
机械模型,没有喜怒哀乐,哪怕用非常简单的甚至不合理的模型(比如在开头例子中,随机选一个打分项作为高权重),最后也有77%的概率比专家们强。
丹尼尔·卡尼曼对此有一句经典评价:“你几乎不可能制造一个比专家表现更差的模型。”

实际上,用“机械判断”,而不是遇事就请教专家,上世纪50年代就有例子。
1953年,麻醉学家阿普加就设计了一个判断新生儿是否健康的模型。也叫阿普加评分(Apgar Scale),一共五个指标:
肤色、心率、刺激反应、肌肉张力、呼吸
然后,医生对每一项进行打分,可以打0分、1分或2分,比如肤色,全身是粉红色给2分,四肢有青紫色给1分,全身青紫色给0分。
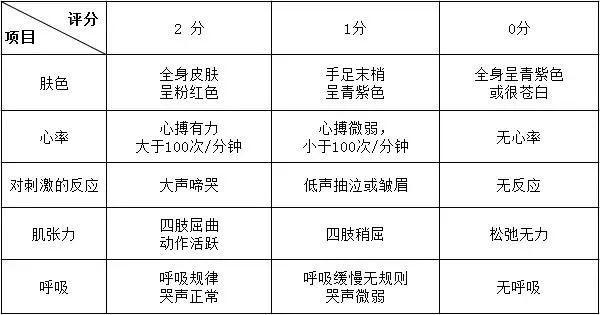
最后只需要把5项得分简单相加就行,不需要加权平均。这个模型满分是10分,只要婴儿总分达到7分,就是健康,4-6分,不太健康,0-3分,需要立刻采取急救措施。
现代医学对癌症的筛查,也都有类似的评分系统,这种分几个维度的判断简单易行,相对不受医生经验和水平的影响,事实证明准确率很高。
但是,一个疑问就自然出现了:既然机械判断这么有效,为什么并没有在各行各业普及开呢?为什么很多时候我们听到的,还是各路专家的意见呢?
比如在医院,大部分诊断还是医生的临床诊断,而不是真的用了模型,而像开头说的招聘场景,或者公司要不要开启一个新的项目,类似这样的决策,“打分法”好像并没有被严肃的采纳过。
这里除了增加就业机会的社会学意义之外(真的都用打分法很多人就要下岗了),还有一个非常重要的原因:
人类对机械判断的容忍度太低了。
试想,如果人类判断错了(事实上专家们几乎天天都在犯错),我们虽然会吐槽,但终究觉得这是正常情况,因为人本来就会犯错;但是如果机械模型错了,或者说算法错了,哪怕就错一两次,我们就会产生质疑,可能再也不敢用了。
这有点像现在的自动驾驶技术。在可以预见的将来,自动驾驶发生事故的概率,一定会比人类司机要低,这是一定的,但是我们内心能容忍人类的事故,却不太能容忍自动驾驶因为程序问题而出事(特斯拉肯定同意这个说法)。

换句话说,我们认为犯错是人类的特权,但机器就不应该犯错。
从这个意义上说,虽然我们“建议专家不要建议”,可是真到了让机器让模型给建议的地步,我们也难免会迟疑。
最后也许我们没有听专家的,却听了亲戚、邻居或者校友的建议(但这些人的建议也并不比专家强),这大概也是一种难以克服的人性——
前面讲了那么多,到头来你也不敢真的相信机器和模型。
比如孩子高考之后填报志愿,全家人在几所高校和几个专业之间举棋不定,很多人在这个时候会选择请教亲朋好友:只要我请教的这个人日常表现很靠谱,那么他的建议应该也靠谱吧?
有没有比这更好的决策方法呢?也许这时你需要一个“无情的机器”。
“网易高考智愿”网站(daxue.163.com)为千万学子家长提供及时专业、深度权威的报考指导,帮助考生把握未来就业方向、职业生涯规划,传授报考方法技巧,更加人性化地切入个人兴趣和未来发展趋势。它能——
智能推荐最适合你的大学和专业
为你解答相关专业的就业前景问题
也能为你带来一手的专业前沿资讯
还会介绍一些很有发展前景的小众专业
点击查看“网易高考智愿”网站使用说明↑
即日起到6月7日0点前,注册“网易高考智愿”网站购买会员卡志愿版/规划版。可尊享早鸟价,获得300元限时立减券!
298元入手原价598元的志愿版会员卡
398元入手原价698元的规划版会员卡
机不可失,为了孩子人生中最重要的决定,赶紧行动吧!
以上就是“建议专家不要建议”为什么是对的?的相关介绍,希望能对你有帮助,如果您还没有找到满意的解决方式,可以往下看看相关文章,有很多“建议专家不要建议”为什么是对的?相关的拓展,希望能够找到您想要的答案。